
[ad_1]
The introduction and socialization of data mesh has caused practitioners, business technology executives and technologists to pause and ask some probing questions about the organization of their data teams, their data strategies, future investments and their current architectural approaches. Some in the technology community have embraced the concept, others have twisted the definition and still others remain oblivious to the momentum building around data mesh.
We are in the early days of data mesh adoption. Organizations that have taken the plunge will tell you that aligning stakeholders is a nontrivial effort — but one that is necessary to break through the limitations that monolithic data architectures and highly specialized teams have imposed on frustrated business and domain leaders. However, practical data mesh examples often lie in the eyes of the implementer and may not strictly adhere to the principles of data mesh. Part of the problem is the lack of open technologies and standards that can accelerate adoption and reduce friction.
This is the topic of today’s Breaking Analysis, where we investigate some of the key technology and architectural questions around data mesh. To do so, we welcome back Zhamak Dehghani, founder of data mesh and director of emerging technologies at ThoughtWorks Holding Inc.

Data priorities in context
Despite the importance of data initiatives, since the pandemic, chief information officers and information technology organizations have had to juggle a few other priorities. It’s why cyber and cloud computing are rated as the two most important priorities in Enterprise Technology Research’s surveys as shown below. Analytics and machine learning/artificial intelligence still make the top of the list – well ahead of many categories — but protecting remote workers and leveraging the cloud remain the most important tactical initiatives for technology leaders.
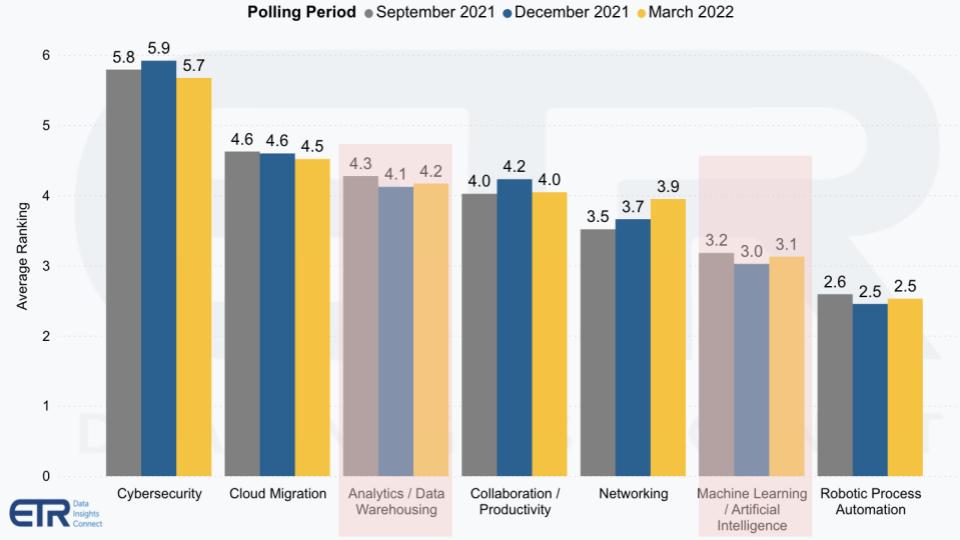
A sound data architecture and strategy are fundamental to digital transformations and much of the past two years, as we’ve often said, have been a forced march to digital. So while organizations are moving forward, they really have to take time to think hard about the data architecture decisions they make because those decisions will affect them for years to come.
Deghani’s perspective on this is the way we use data is expanding and the challenges are shifting:
We are moving [slowly moving] from reason-based, logical algorithmic decision making to model-based computation and decision-making where we exploit the patterns and signals within the data. So data becomes a very important ingredient of not only decision-making and analytics and discovering trends but also the features and applications that we build for the future so we can’t really ignore it. And as we see some of the existing challenges around getting value from data is no longer access to computation but rather access to trustworthy, reliable data at scale.
Listen to Dehghani explain the change in how we use data.
The technology dimensions of data mesh compared with existing architectures
Dehghani recently published her new book, “Data Mesh, Delivering Data-Driven Value at Scale.” In a recent presentation she pulled excerpts from the book and we’re going to talk through some of the technology and architecture considerations. As background, remember there are four key principles of data mesh:
- Domain-driven ownership of data;
- Data as a product;
- Self-serve data platform;
- Federated computational governance.
Organizations that have implemented data mesh will tell you that getting the organization to agree on domain ownership and what exactly are data products and subproducts is compulsory prior to addressing the technical challenge. In many ways, solving for the first two principles creates technical challenges that are surfaced in principles 3 and 4.
Self-serve data platform – serving decentralized teams
The move to a decentralized data architecture immediately changes the dynamic for how data is shared and managed in a scale-out model. And this changes the requirements for the platform, as described below:

Dehghani describes the role of the platform as follows:
The role of the platform is to lower the cognitive load for domain teams, for people who are focusing on the business outcomes. The technologies that are building the applications to really lower the cognitive load for to be able to work with data whether they are building analytics, automated decision-making, intelligent modeling.… They need to be able to get access to data and use it. So the role of the platform, just stepping back for a moment, is to empower and enable these teams. Data mesh by definition is a scale-out model. It is a decentralized model that wants to give autonomy to cross functional teams. So at its core, it requires a set of tools that work really well in that decentralized model. When we look at the existing platforms, they try to achieve the similar outcome right? Lower the cognitive load, give tools to data practitioners to manage data at scale. Because today, looking at centralized teams, their job isn’t really directly aligned with one or two business units and business outcomes in terms of getting value from data. Their job is to manage the data and make the data available for those cross functional teams or business units to use the data.
So the platforms they’ve been given are really centralized around, or tuned to work with, this structure of a centralized team. And although on the surface it seems that “why not, why can’t I use my cloud storage or computation or data warehouse in a decentralized way?” You should be able to, but there’s still some changes need to happen to those underlying platforms. As an example, some cloud providers simply have hard limits on the number of storage accounts that you can have because they never envisaged having hundreds of lakes. They envisage one or two, maybe 10 lakes, right? They envisage really centralizing data, not decentralizing data. So I think we will see a shift in thinking about enabling autonomous independent teams versus a centralized team.
Listen to Dehghani explain the role of the platform in serving decentralized teams.
Treating code, data and policy as a single unit to support scale
The next area we addressed is how to decompose and recompose the functional and technical areas that serve autonomous and interoperable data products. The premise is that in order to scale, code, data and policy must be treated as one unit, whereas existing platforms have independent management for catalogs or storage or the like.

Dehghani explains this concept in detail as follows:
If you think about that functional/technical decomposition of concerns, that’s one way, a very valid way, of decomposing complexity and concerns; and then build solutions – independent solutions – to address them. That’s what we see in the technology landscape today. We will see technologies that are taking care of your management of data, bring your data under some sort of control and modeling. You’ll see technology that moves that data around or perform various transformations and computations on it. And then you see technology that tries to overlay some level of meaning, metadata, understandability, history and policy. Right? So that’s where your data processing pipeline technologies versus data warehouse, storage/lake technologies and then the governance come to play. And over time we decompose and recompose, deconstruct and reconstruct back these elements back together. Right now that’s where we stand.
I think for data mesh to become a reality as independent sources of data, where teams can responsibly share data in a way that can be understood – right then and there – can impose policies right when the data gets accessed in that source, and in a resilient manner, in a way that changes to the structure of the data or changes to the schema of the data doesn’t have those downstream downtime effects…. We’ve got to think about this new nucleus or new units of data sharing and we need to really bring that transformation governing data and the data itself together around these decentralized nodes on the mesh. So that’s another deconstruction and reconstruction that needs to happen around the technology to formulate ourselves around the domains and again the data and the logic of the data itself, the meaning of the data itself.
Treating application and data stacks as a single experience
Today’s application and data stacks are separate. We fence off the application and databases from the analytics, extract the data we need, transform it and then go to work in the data pipeline. The next area we’ll cover focuses on the idea that to make applications more intelligent, the code, data and policy must be embedded into the applications as a single continuous unit.

According to Dehghani:
This topic again has a historical background. For a really long time applications have dealt with features and the logic of running the business. And encapsulating the data in the state that they need to run that feature or run that business function.
And then we had separate data for anything analytical-driven, which required access to data across these applications and across the longer dimension of time or around different subjects within the organization. We had made a decision that, “OK, let’s leave those applications aside, let’s leave those databases aside. We will extract the data out and we’ll load it, transform it and put it under the analytical data stack. And then downstream from it we will have analytical data users, the data analysts, data scientist and the portfolio of users that are growing, use that data stack.” And that led to this separation of dual stacks with point-to-point integration.
So applications went down the path of transactional databases or even document store, for example. But using APIs for communicating. And then we’ve gone to lake storage or data warehouse on the other side [data science or analytics]. And that again enforces the silo of data versus app.
If we are moving to the world where our ambitions are to make applications more intelligent, making them data driven, then these two worlds need to come closer: ML analytics gets embedded into those applications themselves and data sharing as an essential ingredient of that gets embedded and gets closer to those applications.
So if you’re looking at this now cross functional app-data-business team, then the technology stacks can’t be so segregated. There has to be a continuum of experience from app delivery to sharing of the data to using that data to embed models back into those applications. And that continuum of experience requires well-integrated technologies.
To give you an example – which actually is in some sense we are moving to that direction – but if we are talking about data sharing or data modeling and applications use one set of APIs, HTTP-compliant or REST APIs.… And on the other hand, you have proprietary SQL like connect to my database and run SQL. And those are two very different models of representing and accessing data. So we kind of have to harmonize or integrate those two worlds a bit more closely to achieve that goal of serving domain-oriented, cross-functional teams.
Listen to Deghani explain the need to integrate app and data stacks.
Serving ‘generalists’ to scale versus a handful of hyperspecialists
Today’s data roles are highly specialized. The premise is that each individual in the data pipeline can efficiently operate on a specific task and work in parallel with others in the system. The challenge in many organizations is that the data team lacks a business context. For certain applications such as reporting, this may not be problematic, but in a world where organizations are building data products that are a fundamental part of the value chain, perhaps even directly monetized, this separation from the business context becomes problematic because, with a small number of specialists, the centralized data pipeline itself becomes a bottleneck.
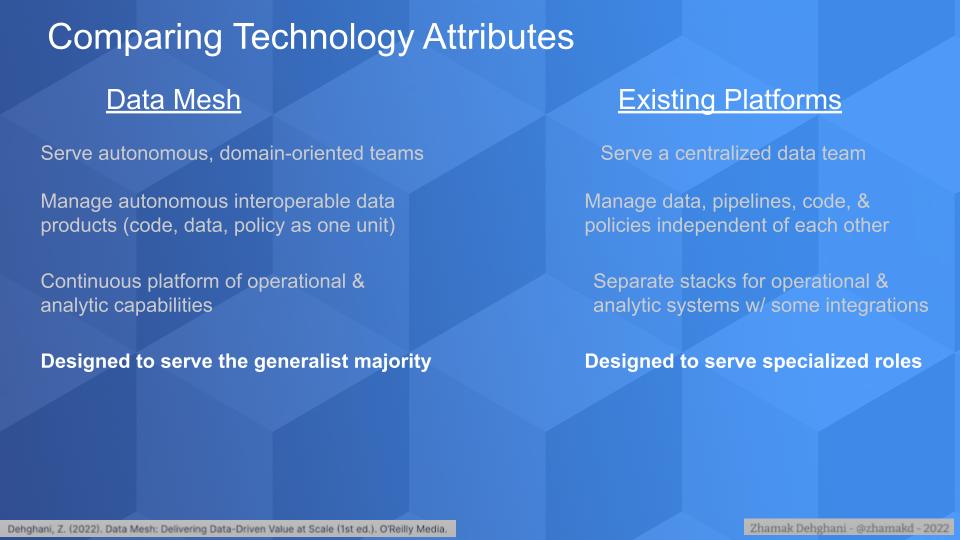
Data mesh envisions a world where line-of-business domain experts — technology generalists — are trained by a select group of specialists and take responsibility for the end to end data lifecycle. In this world, the underlying technology complexities are hidden and serve the business. It’s essentially flipping today’s model on its head.
Dehghani explains as follows:
The intention behind data mesh was creating a responsible data sharing model that scales out. I challenge any organization that has scale ambitions around usage of data to [meet its goals] by relying on small pockets of very expensive specialist resources. Right? So we we have no choice but upskilling and cross-skilling the majority population of our technologists. We often call them generalists, right? That’s shorthand for people who can really move from one technology domain to another.
And you know, sometimes we call them “paint drip” people, sometimes we call them “T-shaped” people, but regardless, we need to have ability to really mobilize our generalists and we had to do that. At ThoughtWorks, we serve a lot of our clients and like many other organizations we also are challenged with hiring specialists. So we have tested the model of having a few specialists really conveying and translating the knowledge to generalists and bringing them forward. And of course platforms is a big enabler of that. Like what is the language of using the technology? What are the APIs that delight that generalist experience?
And this doesn’t mean no-code/low-code. It doesn’t mean we have to throw away good engineering practices — I think good software engineering practices remain. Of course they get adopted to the world of data to build resilient and sustainable solutions. But specialty, especially around proprietary technology, it’s gonna be a hard one to scale.
Decentralization is at the heart of data mesh
Data mesh is based on the concept of scaling out and leans heavily toward decentralization to support domain ownership over centralized monolithic data management approaches. We see the public cloud players, many database companies, which are key actors here touting large installed bases, pushing a centralized approach. Although to quote Microsoft Corp. Chief Executive Satya Nadella, “We’ve reached peak centralization.”

Dehghani commented on this point with the following statement:
If you look at the history of places in our industry where decentralization has succeeded, they heavily relied on standardization of connectivity across different components of technology. And I think right now, you’re right, the way we get value from data relies at the end of the day, on a collection of data. Whether you have a deep learning/machine learning model that you’re training or you have reports to generate.… Regardless. the model is bring your data to a place that you can collect it so that you can use it and that leads naturally to a set of technologies that try to operate as a full stack, integrated, proprietary with no intention of opening data for sharing.
If you now conversely think about internet itself, the web itself, microservices – even at the enterprise level, not at the planetary level — they succeeded as decentralized technologies to a large degree because of their emphasis on openness and openness and sharing — API sharing.
In the API world, we don’t say, “I will build a platform to manage your logical applications.” Maybe to a degree. We actually moved away from that. We say, “I will build a platform that opens around applications to manage your APIs, manage your interfaces, give you access to APIs.” So I think the definition of decentralized there means really composable, open pieces of the technology that can play nicely with each other rather than a full stack all have control of your data… yes, being somewhat decentralized within the boundary of my platform. But that’s just simply not going to scale if data needs to come from different platforms, different locations, different geographical locations. It needs a rethink.
Listen to Dehghani’s perspective on the importance of decentralization.
Creating a domain-agnostic platform to serve business teams
The final point is data mesh favors technologies that are domain-agnostic versus those that are domain-aware. We asked Zhamak to help square the circle on this one because it’s nuanced. For example, data mesh observes that today’s data pipeline teams lack context of the domain and that is problematic. So one would think domain awareness would be an appealing attribute.
What Dehghani explains below is the technology attributes of the platform specifically, meaning the underlying complexity of those data technologies should be both hidden and agnostic to specific use cases to enable data sharing.

Here’s how Dehghani explains:
So as you said, data mesh tries to give autonomy and decision making power and responsibility to people that have the context of those domains, right? The people who are really familiar with different business domains and naturally the data that domain needs or that data the domain shares.
So if the intention of the platform is really to give the power to people with most relevant and timely context. The flat platform itself naturally becomes a shared component that is domain agnostic to a large degree. Of course, those domains can build — platform is a fairly overloaded word– if you think about it as a set of technology that abstracts complexity and allows building the next-level solutions on top. Those domains may have their own set of platforms that are very much domain agnostic. But as a generalized, sharable set of technologies or tools that allows us to share data, that piece of technology needs to relinquish the knowledge of the context to the domain teams and actually becomes domain-agnostic.
Closing technology and standardization gaps
Let’s shift gears and talk about some of the gaps and necessary standards to bring the data mesh vision to life. Dehghani created the following graphic and explains it in detail below:
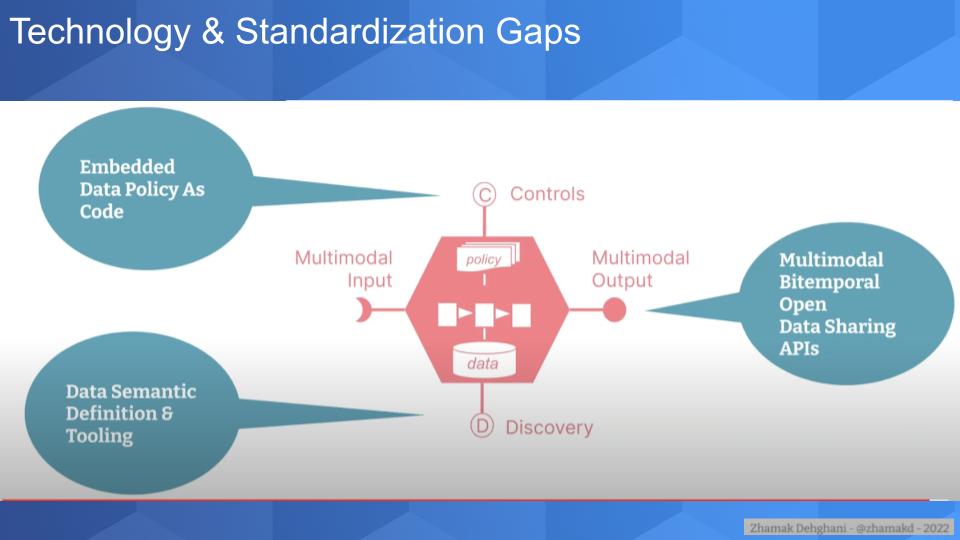
So what I’m trying to depict here is that if we imagine a world where data can be shared from many different locations for a variety of analytical use cases. Naturally the boundary of what we call a node on the mesh will encapsulates internally a fair few pieces. It’s not just the boundary of that node on the mesh, it is the data itself that it’s controlling and updating and maintaining, it’s the computation and the code that’s responsible for that data and then the policies that continue to govern that data as long as that data exists. So if that’s the boundary, then if we shift that focus from implementation details – we can leave that for later – what becomes really important is the seam or the APIs and interfaces that this node exposes. And I think that’s where the work that needs to be done and the standards that are missing.
And we want the seam and those interfaces to be open because that allows different organizations with different boundaries of trust to share data. Not only to share data to move that data to yet another location, but to share the data in a way that distributed workloads, distributed analytics, distributed machine learning models can happen on the data where it is. So if you follow that line of thinking around the decentralization and connection of data versus collection of data, I think the very, very important piece of it that needs really deep thinking – and I don’t claim that I have done that – is how do we share data responsibly and sustainably so that it’s not brittle?
If you think about it today, the ways we share data – one of the very common ways – is “I’ll give you a JDBC endpoint or an endpoint to your database of choice and now I, as as a technology user can actually have access to this schema of the underlying data and then run various queries or simple queries on it.” That’s very simple and easy to get started with.
That’s why SQL is an evergreen standard or semistandard that we all use. But it’s also very brittle because we are dependent on an underlying schema and formatting of the data that’s being designed to tell the computer how to store and manage the data.
So I think that the data-sharing APIs of the future need to think about removing these brittle dependencies. Think about sharing not only the data but what we call metadata. Additional set of characteristics that is always shared along with data to make the data usage ethical and also friendly for the users.
Also the other element of that data-sharing API is to allow computation to run where the data exists. So if you think about SQL again as a simple primitive example of computation — when we select and when we filter and when we join the computation is happening on that data. So maybe there is a next level of articulating distributed computation on data that simply trains models right? Your language primitives change in a way to allow sophisticated analytical workloads to run on the data more responsibly with policies and access control in force. So I think that output port that I mentioned simply is about next-generation data sharing, responsible data sharing. It’s APIs suitable for decentralized analytical workloads.
Listen to Dehghani detail the technology and standards gaps that need to be filled.
Data mesh is not theory
We couldn’t let Zhamak go without addressing some of the controversy that she has created. We see that as a sign of progress, by the way. This individual named Paul Andrew, who is an architect, gave a presentation recently and he teased it as “The theory from Zhamak Dehghani versus the practical experience of a technical architect,” AKA him.

Zhamak was quick to shoot back that data mesh is not theory and it’s based on practice and some practices are experimental and some are more baked. Data mesh avoids, by design, specificity of vendor or technology. And her “mic drop” line was “Perhaps you intend to frame your post as a technology or vendor-specific implementation.” Which was the case.
Dehghani doesn’t need us to defend her practical knowledge, but we will point out she has spent 14-plus years as a software engineer and the better part of a decade consulting with some of the most technically advanced companies in the world with ThoughtWorks.
But we pushed Zhamak a bit here that some of this tension is of her own making because she purposely doesn’t talk about technologies and vendors– at least not publicly. And sometimes doing so is instructive. We asked her why she didn’t provide specific vendor examples.
My role in this battle is to push us to think beyond what’s available today. Of course, that’s my public persona. On a day-to-day basis, actually I work with clients and existing technology and at Thoughtworks we have given a case study talk with a colleague of mine and I intentionally got him to talk about the technology that we use to implement data mesh. And the reason I haven’t really embraced, in my conversations, the specific technology…. One is, I feel the technology solutions we’re using today are still not ready for the vision.
I mean, we have to be in this transitional step, no matter what we have to be pragmatic, of course, and practical, I suppose. And use the existing vendors that exist and I wholeheartedly embrace that, but that’s just not my role, to show that. I’ve gone through this transformation once before in my life. When microservices happened, we were building microservices like architectures with technology that wasn’t ready for it. Big application, web application servers that were designed to run these giant monolithic applications. And now we’re trying to run little microservices on them. And the tail was wagging the dog. The environmental complexity of running these services was consuming so much of our effort that we couldn’t really pay attention to that business logic, the business value.
And that’s where we are today. The complexity of integrating existing technologies is really overwhelmingly capturing a lot of our attention and cost and effort, money and effort as opposed to really focusing on the data product themselves. So it’s just that’s the role I have, but it doesn’t mean that we have to rebuild the world. We’ve got to do with what we have in this transitional phase until the new generation of technologies comes around and reshape our landscape of tools.
In the linkedIn post, there were some other good comments, one from a guy who said the most interesting aspects of data mesh are organizational. That’s how our colleague Sanjeev Mohan frames data mesh versus data fabric. We’re not clear on data fabric, as we still think data fabric in terms of what NetApp defined as software-defined storage infrastructure that can serve on-premises and public cloud workloads.
Can data mesh avoid being co-opted by wealthy company marketing?
This topic is highly nuanced, and new. People are going to shoehorn data mesh into their respective views of the world – you’re seeing this with lakehouses, cloud data warehouses, S3 buckets and the big cloud players that have a stake in the game. We warned Dehghani that she’s going to have to enlist a serious army of enforcers to adjudicate the purity of data mesh.
We asked her: How realistic is it that the clarity of her vision can be implemented and not polluted by really rich technology companies and others?
Is it even possible, right? That’s a yes. That’s why I practice Zen. I think, it’s going to be hard. What I’m hopeful, is at the socio-technical level, data mesh is a socio-technical concern or solution, not just a technology solution. Hopefully it always brings us back to the reality that vendors try to sell you safe oil that solves all of your problems. (Chuckles.) All of your data mesh problems. It’s just going to cause more problems down the track. So we’ll see, time will tell, Dave, and I count on you as one of those members of, you know, folks who will continue to share their platform.
To go back to the roots, as why in the first place? I mean, I dedicated a whole part of the book to “Why?” Because we get carried away with vendors and technology solutions try to ride a wave. And in that story, we forget the reason for which we are even making this change and we are going to spend all of these resources. So hopefully we can always come back to that.
Listen to Dehghani’s hope for the future of data mesh.
It is a tall order. Some large data-driven companies are leaning in — JPMC, Intuit, HelloFresh, Zalando, Netflix — so there’s some real momentum. Monte Carlo has built a data mesh “best fit” calculator. Starburst is leaning in. ChaosSearch sees itself as an enabler to solve some of the problems we discussed today. Oracle and Snowflake use the term data mesh, which does make some purists wince. And the Data Mesh Learning community is doing its part and growing.
The movement is gaining momentum and we’re here tracking it.
Keep in touch
Thanks to Stephanie Chan who researches topics for this Breaking Analysis. Alex Myerson is on production, the podcasts and media workflows. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Robert Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email [email protected], DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at [email protected].
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Image: BNMK0819
Show your support for our mission by joining our Cube Club and Cube Event Community of experts. Join the community that includes Amazon Web Services and Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
[ad_2]
Source link